Welcome to this comprehensive guide on word embedding in PyTorch + Lightning. In this guide, we will explore the concept of word embedding and how to build and train a word embedding network using PyTorch + Lightning. By the end, you will have a solid understanding of word embedding and the tools to create your own word embedding networks.
Contents
Introduction
Word embedding is a technique used in natural language processing (NLP) to represent words or phrases as dense vectors of real numbers. It allows us to capture the semantic meaning of words and their relationships in a mathematical space. Word embedding has become a valuable tool in various NLP tasks, such as language translation, sentiment analysis, and information retrieval.
In this guide, we will focus on word embedding in PyTorch + Lightning, a popular framework for deep learning. We will learn how to build and train a word embedding network from scratch using tensors and basic math, as well as simplify the code using PyTorch’s nn.Linear function. Additionally, we will explore how to use pre-trained word embeddings and the nn.Embedding function in PyTorch.
Building a Word Embedding Network from Scratch
Initializing the Network
To begin, let’s create a simple word embedding network from scratch using PyTorch tensors and basic math. First, we import the necessary libraries:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsNext, we define the input and label tensors. For example, let’s create word embeddings for the sentences “Troll 2 is great” and “Jim Kata is great”. Each unique token in the training data will have a corresponding input tensor. We convert the input lists into tensors using torch.tensor:
inputs = torch.tensor([[1, 0, 0, 0], # Troll 2
[0, 1, 0, 0], # is
[0, 0, 1, 0], # great
[0, 0, 0, 1]]) # Jim Kata
labels = torch.tensor([[0, 1, 0, 0], # is
[0, 0, 1, 0], # great
[0, 0, 0, 1], # Jim Kata
[0, 0, 0, 0]]) # No predictionCreating the Word Embedding Network
Now let’s define the word embedding network. We’ll create a class called WordEmbedding that inherits from nn.Module:
class WordEmbedding(nn.Module):
def __init__(self):
super(WordEmbedding, self).__init__()
self.weights = nn.Parameter(torch.empty((4, 2)))
def forward(self, x):
hidden = torch.matmul(x, self.weights)
return hidden
model = WordEmbedding()In the __init__ method, we define a weight matrix using nn.Parameter. This weight matrix represents the word embeddings. In the forward method, we perform matrix multiplication between the input tensor x and the weight matrix self.weights to obtain the hidden representation of the words.
Training the Word Embedding Network
To train the word embedding network, we need to define the training loop. We’ll use the cross-entropy loss function, which quantifies the difference between the predicted output and the ground truth. Here’s the training loop:
optimizer = optim.Adam(model.parameters(), lr=0.1)
criterion = nn.CrossEntropyLoss()
for epoch in range(100):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels.argmax(dim=1))
loss.backward()
optimizer.step()In each epoch, we reset the gradients, compute the outputs of the model, calculate the loss, perform backpropagation, and update the weights using the optimizer. The goal is to minimize the loss by adjusting the word embeddings.
Analyzing the Word Embeddings
Once the training is complete, we can analyze the word embeddings. We’ll visualize the word embeddings using a scatter plot:
embedding_values = model.weights.detach().numpy()
tokens = ['Troll 2', 'is', 'great', 'Jim Kata']
df = pd.DataFrame(embedding_values, index=tokens, columns=['x', 'y'])
plt.scatter(df['x'], df['y'])
for token, x, y in zip(tokens, df['x'], df['y']):
plt.text(x, y, token, ha='center', fontsize=8)
plt.xlabel('Embedding Dimension 1')
plt.ylabel('Embedding Dimension 2')
plt.title('Word Embeddings')
plt.show()This scatter plot visualizes the word embeddings in a 2-dimensional space, with each point representing a word or token. We can see the relationship between the words based on their proximity in the plot.
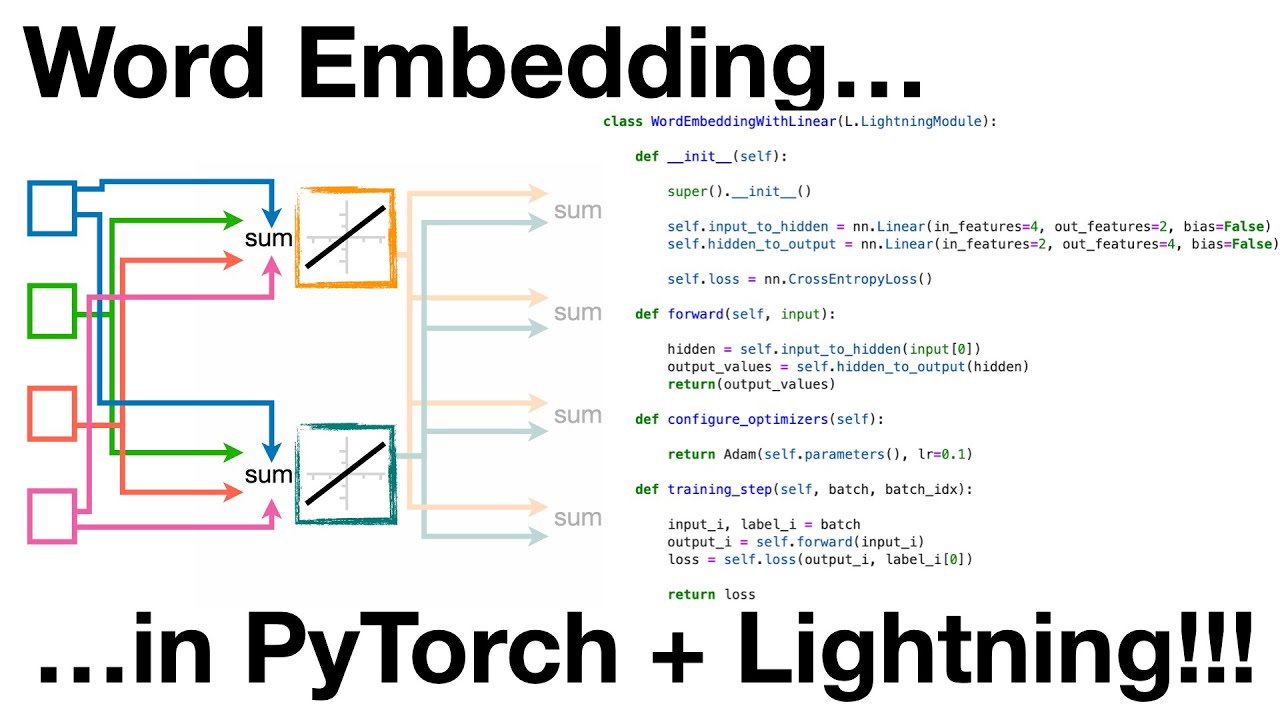
Using nn.Linear to Simplify the Code
The previous example involved manual computation and matrix multiplication. However, PyTorch provides a convenient function called nn.Linear that simplifies the code. Here’s how we can modify the WordEmbedding class:
class WordEmbedding(nn.Module):
def __init__(self):
super(WordEmbedding, self).__init__()
self.embedding = nn.Linear(4, 2, bias=False)
def forward(self, x):
hidden = self.embedding(x)
return hiddenIn the __init__ method, we replace the weight matrix with an nn.Linear module. The nn.Linear module automatically initializes the weight matrix with the specified dimensions. In the forward method, we directly pass the input tensor x to the nn.Linear module.
The training loop and the analysis of word embeddings remain the same.
Loading and Using Pre-trained Word Embeddings
PyTorch also allows us to load and use pre-trained word embeddings using the nn.Embedding module. Let’s see how we can do this:
pretrained_weights = torch.tensor([[0.38, 0.42],
[0.11, 0.21],
[0.83, 0.76],
[0.95, 0.91]])
word_embeddings = nn.Embedding.from_pretrained(pretrained_weights.t())
input_token = 'Troll 2'
input_index = tokens.index(input_token)
embedding = word_embeddings(torch.tensor([input_index]))
print(embedding)In this example, we create an nn.Embedding object called word_embeddings using the pre-trained weights. We transpose the pre-trained weights using t() to match the shape expected by nn.Embedding. Then, we select an input token (e.g., “Troll 2”) and obtain its corresponding index. Finally, we pass the index to word_embeddings to get the embedding vector for that token.
Conclusion
Word embedding is a powerful technique for representing words or phrases as dense vectors. In this guide, we learned how to build and train word embedding networks from scratch using PyTorch + Lightning. We also explored how to simplify the code using nn.Linear and how to load and use pre-trained word embeddings with nn.Embedding. Now you have the knowledge and tools to create your own word embedding networks and leverage their power in various NLP tasks.
If you want to learn more about word embedding, statistics, machine learning, or PyTorch, feel free to check out our website Techal for more informative articles, guides, and resources. Happy embedding!
