By Techal
Welcome to another exciting installment of our NLU and IR series! In this episode, we dive into the fascinating world of neural IR and explore the late interaction paradigm. This paradigm offers a unique approach to achieving high effectiveness and low computational cost in information retrieval tasks. So let’s get started!
Contents
The Representation Similarity Paradigm
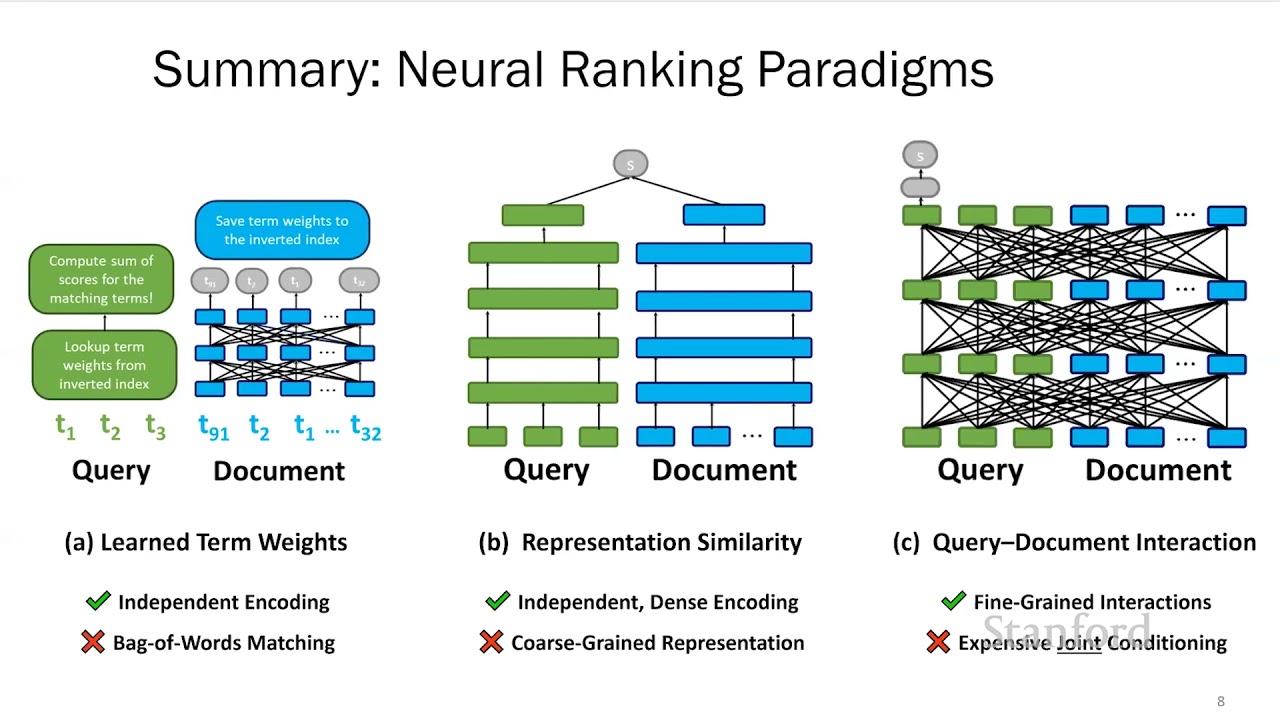
The representation similarity paradigm is one of the efficient ways to build neural IR models. In this paradigm, we tokenize the query and document separately and feed them through an encoder like BERT. The encoder produces a single-vector representation for each query and document. This representation is then used to calculate the relevant score between the query and the document.

Introducing Late Interaction
While representation similarity models have their advantages, they suffer from two major downsides: single-vector representations and lack of fine-grained interactions during matching. To overcome these limitations, we introduce the late interaction paradigm.
Late interaction allows us to combine the efficiency benefits of precomputation with the fine-grained term level interactions of models like BERT. It involves independently encoding the query and document into fine-grained representations using BERT. Then, we calculate a similarity score for each query term by finding the maximum cosine similarity with the document embeddings. The final score for the document is obtained by summing these maximum similarity scores.

ColBERT: A Late Interaction Model
ColBERT is an example of a model that utilizes the late interaction paradigm on top of BERT. It represents each document as a dense matrix of vectors, with one vector per token. By using maximum similarity operators, ColBERT contextually matches query terms in the document and assigns a matching score for each term.
ColBERT achieves comparative quality with BERT at a fraction of the computational cost. It allows for end-to-end retrieval across large collections, maintaining subsecond latencies while offering much higher recall. This is a significant advantage over traditional re-ranking pipelines.
Evaluating ColBERT’s Performance
ColBERT has been evaluated in both in-domain effectiveness evaluations and out-of-domain settings. In in-domain evaluations on the MS MARCO dataset, ColBERT performs on par with BERT and other term level interaction models while being computationally efficient. In a zero-shot setting using the BEIR benchmark, ColBERT consistently outperforms single vector approaches, demonstrating its robustness and scalability.
FAQs
Q: How does ColBERT compare to other representation similarity models like DPR and SBERT?
A: In evaluations across various IR tasks, ColBERT consistently performs on par with or surpasses DPR and SBERT. It showcases the importance of fine-grained term level interactions for achieving high recall and robustness.
Q: Can ColBERT be used in new out-of-domain settings without training data?
A: Yes, ColBERT can be deployed in zero-shot settings. It has shown impressive performance when applied to new IR tasks without any fine-tuning or retraining.
Q: How does ColBERT handle large collections?
A: ColBERT’s late interaction mechanism allows for efficient end-to-end retrieval across large document collections. It scales well, maintaining subsecond latencies while achieving high recall.
Conclusion
Late interaction is a powerful paradigm that combines the efficiency benefits of precomputation with the fine-grained term level interactions of models like BERT. ColBERT, an example of a late interaction model, offers impressive performance in information retrieval tasks, achieving high recall and quality while being computationally efficient. It paves the way for future advancements in neural IR research.
To delve deeper into the fascinating world of technology, visit Techal. Stay tuned for our next episode, where we explore how scalability can drive large gains in quality within retriever models.