Welcome to the second part of our series on Clustering and Classification! In this article, we will be discussing the K-means algorithm, which is one of the most important algorithms in the unsupervised learning literature.
Contents
Understanding the K-means Algorithm
The K-means algorithm is simple yet powerful. It is widely used because it is easy to program, fast, and effective for clustering data. Unsupervised learning algorithms like K-means aim to find clusters in data without prior knowledge of the number of clusters or their existence. This makes K-means an essential tool for analyzing data patterns.
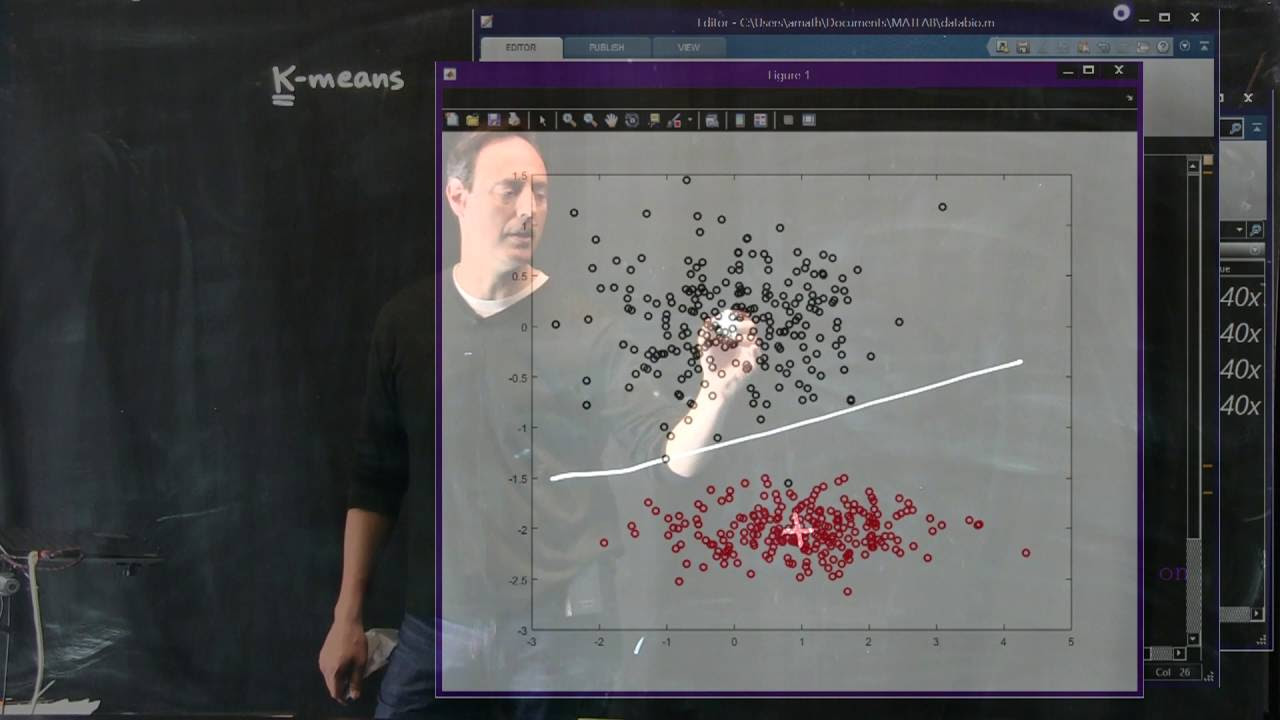
To illustrate the concept of K-means, let’s consider a toy problem. We will generate two types of data sets, each following a Gaussian distribution. Our goal is to see how well the K-means algorithm can identify the clusters and separate them.
Implementing the K-means Algorithm with MATLAB
To demonstrate the K-means algorithm, let’s switch to MATLAB. We will first generate two sets of randomly distributed points, which we will label as “cats” and “dogs.”
Using MATLAB’s built-in K-means algorithm, we can easily implement the clustering process. The algorithm requires the number of clusters as an input. In our case, we will set it to two, as we want to find two clusters.
After running the algorithm, we will obtain a binary output, where each data point is labeled as either belonging to cluster one or cluster two. By collecting the points labeled as cluster one and cluster two, we can visualize the separation of the data.
Conclusion
The K-means algorithm is a powerful tool for clustering data. It allows us to identify and separate clusters without prior knowledge of the data structure. By leveraging the simplicity and speed of MATLAB’s K-means algorithm, we can easily apply it to various data sets and gain valuable insights.
If you want to learn more about the K-means algorithm and its applications, be sure to visit Techal for more informative articles and useful guides.
FAQs
Q: What is the K-means algorithm?
A: The K-means algorithm is an unsupervised machine learning algorithm used for clustering data. It aims to partition data points into K different clusters based on their similarity.
Q: How does the K-means algorithm work?
A: The K-means algorithm starts by randomly selecting K initial centroids. It then assigns each data point to the nearest centroid and updates the centroids’ positions based on the mean of the assigned data points. This process iteratively repeats until the centroids no longer move significantly.
Q: How do I determine the optimal value for K?
A: Determining the optimal value for K can be challenging. One common approach is to use the elbow method, which involves plotting the within-cluster sum of squares (WCSS) against the number of clusters K and selecting the value of K at the “elbow” of the plot, where the decrease in WCSS starts to level off.
Q: What are some real-world applications of the K-means algorithm?
A: The K-means algorithm has a wide range of applications, including customer segmentation, image compression, anomaly detection, and document clustering.
Q: Can the K-means algorithm handle high-dimensional data?
A: Yes, the K-means algorithm can handle high-dimensional data. However, the curse of dimensionality can affect its performance. Preprocessing techniques like dimensionality reduction or feature selection can be used to improve the algorithm’s efficiency.
Q: Are there any limitations of the K-means algorithm?
A: The K-means algorithm assumes that clusters are spherical, equally sized, and have the same density, which might not hold in all cases. It is also sensitive to the initial centroid positions and can converge to suboptimal solutions. Additionally, the choice of K can greatly impact the clustering results.
