Have you ever wondered how a computer determines the similarity or difference between two pieces of text? With a large amount of data, relying on human analysis becomes impractical. That’s where cosine similarity comes in. In this article, we will explain this concept in a clear and concise manner.
Contents
The Basics of Cosine Similarity
Cosine similarity is a metric that allows computers to measure the similarity between different pieces of text. It is a relatively simple calculation that provides valuable insights into how similar or different two texts are.
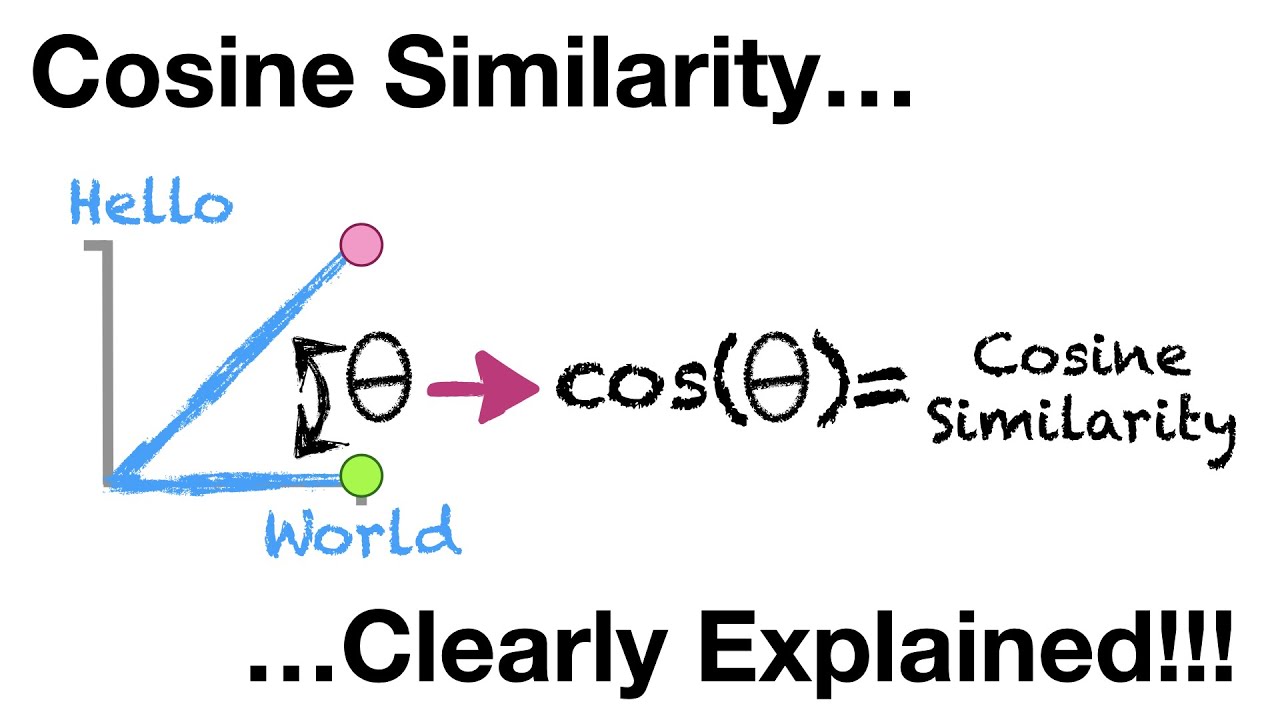
To understand how cosine similarity works, let’s start with a basic example. Imagine we have two phrases, “hello world” and “hello”. To calculate their similarity, we first create a table that counts the occurrences of each word in the phrases.
| Phrase | hello | world |
|---|---|---|
| hello world | 1 | 1 |
| hello | 1 | 0 |
Using this table, we can plot the points on a two-dimensional graph. The x-axis represents the number of occurrences of the word “hello”, and the y-axis represents the number of occurrences of the word “world”.
If we draw lines from the origin of the graph (0, 0) to the points, we can see that the angle between the lines is 45 degrees. The cosine of a 45-degree angle is 0.71, which represents the cosine similarity between the phrases “hello world” and “hello”.
Understanding the Formula
Although manually calculating cosine similarity can be time-consuming, there is a formula that simplifies the process. Let’s break down the equation step by step:
cosine similarity = (Σ(Ai * Bi)) / (√(Σ(Ai^2)) * √(Σ(Bi^2)))In this equation:
- Ai and Bi represent the word counts for each word in the phrases.
- Σ denotes the summation of the values.
- N represents the number of different words in the phrases.
By plugging in the word counts for the respective words and performing the calculations, we arrive at the cosine similarity value.
Handling More Complex Texts
What happens when we have phrases with more than two words? Visualizing these points on a graph becomes challenging, as we would require more than two dimensions. However, the equation for cosine similarity comes to the rescue. Instead of struggling to plot points in multiple dimensions, we can simply plug the values into the formula.
For example, if we wanted to calculate the cosine similarity between the phrases “I love Troll 2” and “I love Jim Kata”, which consist of five different words, we can directly apply the formula. The resulting cosine similarity is 0.58.
FAQs
Q: What is cosine similarity?
A: Cosine similarity is a metric used to measure the similarity between two pieces of text. It calculates the angle between the lines formed by the word counts of each word in the text.
Q: How is cosine similarity calculated?
A: Cosine similarity is calculated using the formula (Σ(Ai * Bi)) / (√(Σ(Ai^2)) * √(Σ(Bi^2))), where Ai and Bi represent the word counts for each word in the phrases.
Q: Can cosine similarity be used for more than two phrases?
A: Yes, cosine similarity can be used for any number of phrases. Instead of visualizing points on a graph, the formula allows us to calculate the similarity directly.
Conclusion
Cosine similarity is a powerful concept that enables computers to understand the similarity or difference between different pieces of text. By calculating the angle between lines formed by word counts, we can quantify similarity. Understanding cosine similarity can empower you to analyze text data more effectively.
To learn more about technology and stay updated with the latest advancements, visit Techal. Happy exploring!
