In the world of data analysis and machine learning, classification trees are widely used to make predictions and classify data based on various features. In this article, we will guide you through the process of building a classification tree, pruning it, and optimizing its performance.
Contents
Introduction
Classification trees are an excellent machine learning method for understanding decision-making processes and exploring data. Although some may consider them less glamorous than other machine learning techniques, they are immensely practical and frequently used in fields such as medicine due to their ability to provide clear rationales for decisions.
In this article, we will start by importing and formatting the data appropriately. Then, we will build a preliminary decision tree and evaluate its performance. After pruning the tree using cost complexity pruning, we will assess its accuracy using cross-validation techniques. Finally, we will interpret and assess the final pruned classification tree.
Importing and Formatting the Data
Before we can start building our classification tree, we need to import and format the data correctly. This involves dealing with missing data and preparing the data for decision tree analysis.
We will use the pandas library to read the data from a CSV file and store it in a DataFrame. Next, we will inspect the data and ensure that it contains the correct column names.
import pandas as pd
# Read the data from a CSV file into a DataFrame
df = pd.read_csv('data.csv')
# Inspect the first five rows to verify the data format
df.head()Preliminary Decision Tree
Now that we have the data properly formatted, we can begin building our preliminary decision tree. This tree is a full-sized tree that may be prone to overfitting the training data.
We will split the data into training and testing subsets using the train_test_split function. Then, we will build a decision tree classifier and fit it to the training data.
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import plot_confusion_matrix
# Split the data into training and testing subsets
X_train, X_test, y_train, y_test = train_test_split(X_encoded, y, random_state=42)
# Build a preliminary decision tree
tree = DecisionTreeClassifier()
tree.fit(X_train, y_train)
# Evaluate the tree using the testing data and plot the confusion matrix
plot_confusion_matrix(tree, X_test, y_test)Pruning the Decision Tree
To improve the performance of our decision tree, we will prune it using cost complexity pruning. Pruning involves finding the optimal value for the pruning parameter alpha, which controls the degree of pruning.
We will extract the different values for alpha available for this tree and build a pruned tree for each value. Then, we will plot the accuracy of the trees as a function of alpha to find the optimal value.
path = tree.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
# Remove the maximum alpha to avoid a fully pruned tree
ccp_alphas = ccp_alphas[:-1]
trees = []
for alpha in ccp_alphas:
pruned_tree = DecisionTreeClassifier(random_state=42, ccp_alpha=alpha)
pruned_tree.fit(X_train, y_train)
trees.append(pruned_tree)
# Plot the accuracy of the trees using the training and testing dataFinal Classification Tree
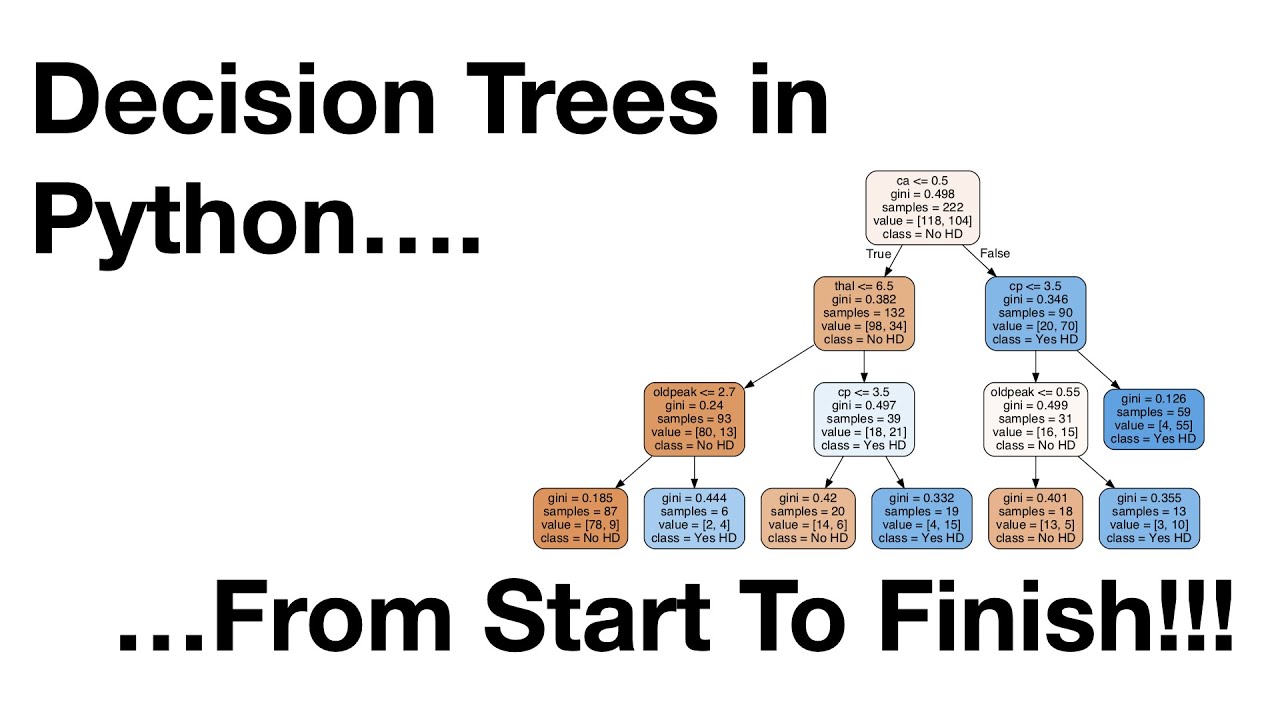
Using cross-validation, we can find the optimal value for alpha to build the final classification tree. Cross-validation allows us to validate the performance of the tree across different training and testing data sets.
We will evaluate the accuracy of the tree using cross-validation and store the optimal alpha value in a variable called ideal_ccp_alpha. Then, we will build, draw, and interpret the final pruned classification tree.
from sklearn.model_selection import cross_val_score
scores = [cross_val_score(tree, X_train, y_train, cv=10).mean() for tree in trees]
ideal_ccp_alpha = ccp_alphas[scores.index(max(scores))]
# Convert ideal_ccp_alpha to a float
ideal_ccp_alpha = float(ideal_ccp_alpha)
# Build the final classification tree using the optimal alpha value
final_tree = DecisionTreeClassifier(random_state=42, ccp_alpha=ideal_ccp_alpha)
final_tree.fit(X_train, y_train)
# Draw the final pruned classification tree and analyze its structureConclusion
In this article, we have explored the process of building a classification tree, pruning it using cost complexity pruning, and optimizing its performance. By using cross-validation, we can ensure that our tree is not overfitting the training data and performs well on unseen data.
Remember, decision trees are a powerful tool for understanding decision-making processes and classifying data. By following the steps outlined in this article, you can build and optimize effective classification trees for your own data analysis projects.
