Welcome back, everyone! Today, we’re going to delve into the fascinating world of supervised sentiment analysis with a focus on the Stanford Sentiment Treebank. This particular dataset is a treasure trove of information when it comes to understanding the sentiment behind sentences.
Contents
The Basics
The Stanford Sentiment Treebank is a sentence-level corpus consisting of approximately 11,000 sentences derived from Rotten Tomatoes movie reviews. Originally released by Pang and Lee in 2005, this dataset has been expanded to include not just the full sentences but also the sub-constituents of each sentence. These sub-constituents are labeled according to traditional syntactic parses.
Crowdsourcing and Labels
One of the standout features of the Stanford Sentiment Treebank is the extensive use of crowdsourcing for labeling. Each sub-constituent in the dataset has been carefully labeled, resulting in a rich source of supervision signals throughout the structure of the examples. The underlying corpus and the labels themselves are five-way classifications extracted from workers’ slider responses.
The Power of the Trees
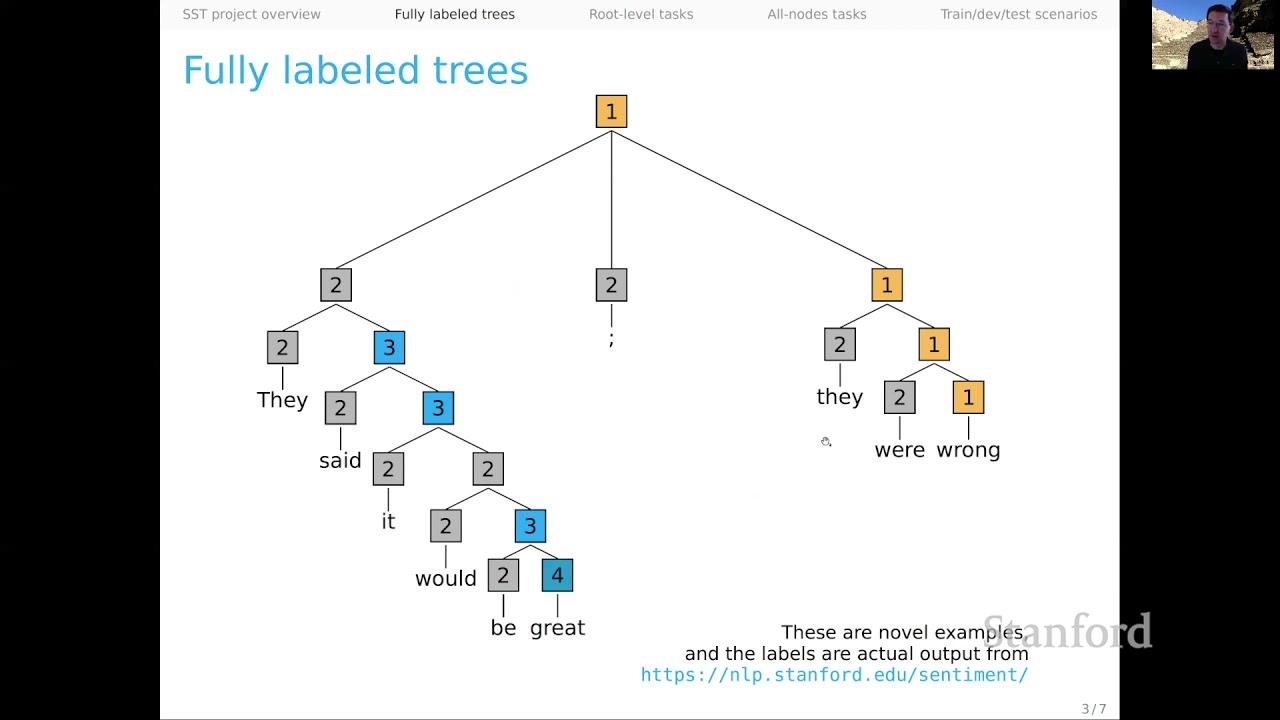
The fully labeled tree structure present in the Stanford Sentiment Treebank is one of the most exciting aspects of this dataset. It allows us to take advantage of the hierarchical nature of sentiment and analyze sentiment not just at the sentence level but also at the sub-constituent level.
For example, let’s take a look at the sentence “NLU is enlightening.” In this case, the verb phrase “is enlightening” is labeled as positive, while the individual words, “NLU” and “is,” are labeled as neutral. The overall contribution of the sentence is considered highly positive.
Sentiment Analysis Challenges
Sentiment analysis is not without its challenges, especially when it comes to understanding the sentiment behind complex sentences. Take the example “They said it would be great.” On its own, “great” would be considered positive. However, when taken in context, the sentiment shifts towards neutrality, as the speaker is not necessarily endorsing the claim of greatness.
Ternary Sentiment Analysis
To address the challenges of sentiment analysis, the Stanford Sentiment Treebank introduces a ternary sentiment classification problem. In this formulation, sentiment labels are grouped into positive, negative, and neutral categories. This approach allows for more nuanced predictions and avoids the false presupposition that every sentence must be classified as either negative or positive.
Binary Sentiment Analysis
Although the ternary sentiment analysis provides more flexibility, it is also common to formulate the problem as a binary classification task. In this case, the sentiment labels are simplified into negative and positive categories, disregarding neutral sentiments. However, this approach can result in some loss of data and may not be suitable for all cases.
Making the Most of the Stanford Sentiment Treebank
The Stanford Sentiment Treebank offers various ways to approach sentiment analysis, whether focusing on the root-level problem or treating each subconstituent as an independent classification task. By leveraging the full dataset and incorporating duplicates, you can enhance the training process and obtain more accurate models.
FAQs
Q: What is the Stanford Sentiment Treebank?
A: The Stanford Sentiment Treebank is a sentence-level corpus consisting of approximately 11,000 sentences from Rotten Tomatoes movie reviews. It includes labels for both the full sentences and their sub-constituents, providing a comprehensive view of sentiment analysis.
Q: How are the labels in the dataset obtained?
A: The labels in the Stanford Sentiment Treebank are obtained through crowdsourcing. Workers provide slider responses, which are then aggregated and transformed into five-way classifications.
Q: What is the advantage of the tree structure in sentiment analysis?
A: The tree structure allows for a more nuanced analysis of sentiment, considering not only the overall sentiment of a sentence but also the sentiment of its sub-constituents. This hierarchical approach provides a deeper understanding of sentiment in natural language.
Conclusion
The Stanford Sentiment Treebank is a valuable resource for anyone interested in sentiment analysis. Its extensive labeling, hierarchical structure, and diverse range of examples make it a powerful tool for training sentiment analysis models. To learn more about working with this dataset and explore its intricacies, check out the provided notebook.
For more articles on the latest technology trends, visit Techal.
