Have you ever found yourself in a situation where you desperately need a good p-value for your research experiment? It’s late at night, and the grant deadline is looming. You’ve finished your experiments, and the p-value you got is 0.05 – the magical number for statistical significance. But before you decide to call it a day, let’s talk about p-hacking and the importance of power calculations.
Contents
The Problem with P-Values
P-values play a crucial role in determining the statistical significance of your results. A p-value of 0.05 or less is generally considered statistically significant, suggesting that the observed effect is unlikely to have occurred by chance. However, it’s essential to understand that p-values can sometimes be misleading.
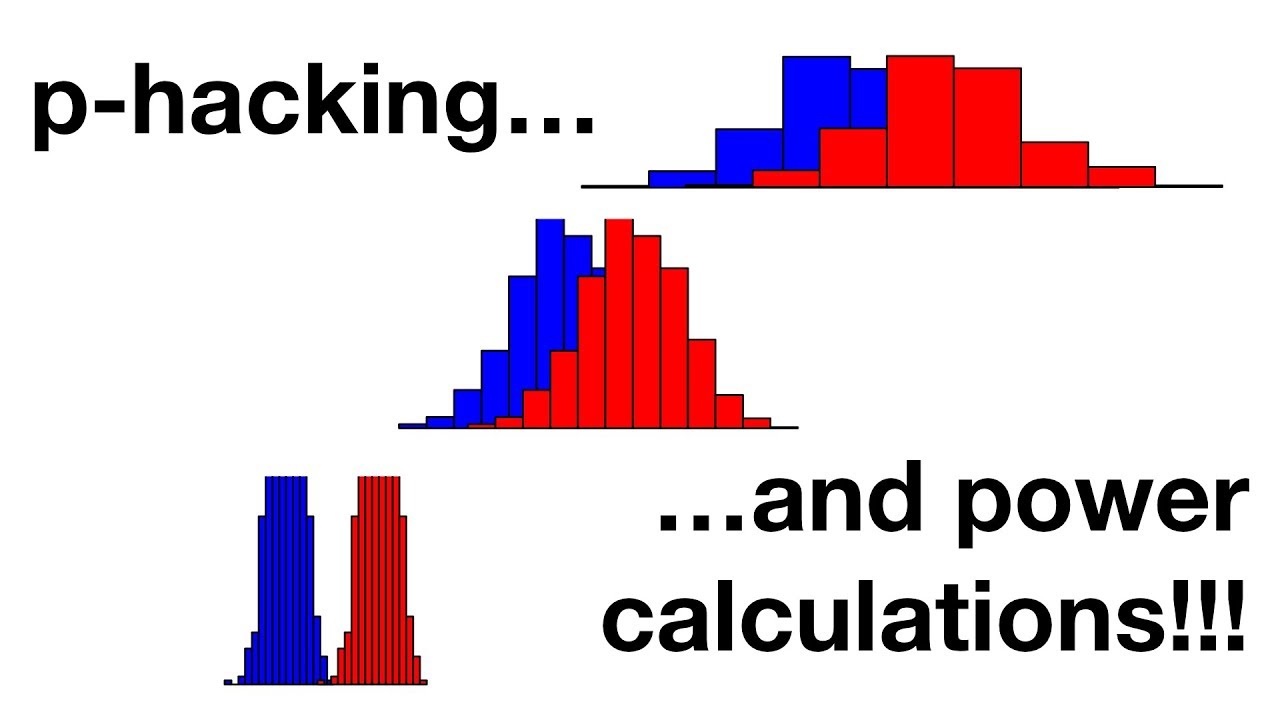
Let’s consider an example using a normal distribution to represent the weights of an inbred laboratory mouse strain. Assuming these weights are from the same distribution, a t-test comparing two samples should yield a p-value greater than 0.05 most of the time. However, occasionally, due to random chance, the two samples might appear significantly different, leading to a p-value less than 0.05. This is known as a false positive.
The Dangers of P-Hacking
In our quest to achieve significant results, we might be tempted to add more samples until we obtain the desired p-value. However, this approach significantly increases the chances of reporting false positives. Just adding samples blindly without considering statistical power can lead to misleading results.
Understanding Power Calculations
To prevent falling into the p-hacking trap, it is essential to perform power calculations before conducting an experiment. Power calculations help determine the necessary sample size to achieve a desired level of statistical power – the probability of correctly detecting a true effect.
There are four main factors that affect statistical power:
- Effect size: The magnitude of the difference between groups or the strength of the relationship.
- Variation in the data: The amount of spread or dispersion in the data.
- Sample size: The number of observations or participants in your study.
- Statistical test: Different tests have varying levels of power.
By understanding these factors, we can make informed decisions about sample size and avoid false positives.
Conducting Power Calculations
To perform power calculations, you need preliminary data or educated guesses about effect sizes and variation in the data. Using this information, you can estimate the standard error, which measures the variation in the means calculated from different samples. The larger the sample size, the smaller the standard error, and the more confidence we have in our estimates.
Several online tools and software can assist you in performing power calculations, taking into account effect size, variation, and sample size.
Conclusion
In summary, p-hacking is a statistical pitfall that can lead to false positives and misleading results. Instead of solely relying on p-values, we must prioritize power calculations to determine appropriate sample sizes. By understanding the four critical factors affecting power – effect size, variation, sample size, and choice of statistical test – we can conduct robust experiments and draw accurate conclusions.
Next time, let’s dive into the fascinating world of false discovery rates and explore the relationship between p-values and their implications. Stay tuned for another exciting Stat Quest!
For more engaging technology content, visit Techal.
FAQs
Q: What is p-hacking?
A: P-hacking refers to the practice of manipulating or cherry-picking data to achieve a desired p-value, leading to false positives and unreliable results.
Q: Why are power calculations important?
A: Power calculations help determine the appropriate sample size needed to achieve a desired level of statistical power, ensuring that experiments have sufficient sensitivity to detect true effects.
Q: How can I perform power calculations?
A: Power calculations require preliminary data or educated guesses about effect sizes and variation. Online tools and software can assist in performing these calculations accurately.
Q: What is statistical power?
A: Statistical power is the probability of correctly detecting a true effect. A study with high power has a greater chance of correctly rejecting the null hypothesis when a true effect exists.
Q: Why is it important to avoid false positives?
A: False positives can lead to incorrect conclusions and wasted resources. By minimizing false positives through robust statistical methods, we ensure the reliability and validity of our research findings.
Conclusion
In summary, p-hacking is a statistical pitfall that can lead to false positives and misleading results. Instead of solely relying on p-values, we must prioritize power calculations to determine appropriate sample sizes. By understanding the four critical factors affecting power – effect size, variation, sample size, and choice of statistical test – we can conduct robust experiments and draw accurate conclusions.
Next time, let’s dive into the fascinating world of false discovery rates and explore the relationship between p-values and their implications. Stay tuned for another exciting Stat Quest!
For more engaging technology content, visit Techal.
