Neural machine learning language translation is an exciting field that enables us to understand and communicate across different languages. In this tutorial, we will explore how to implement sequence-to-sequence learning using machine learning and Keras. By the end of this tutorial, you will have a solid understanding of how to build a language translation model.
Contents
Understanding Encoder and Decoder
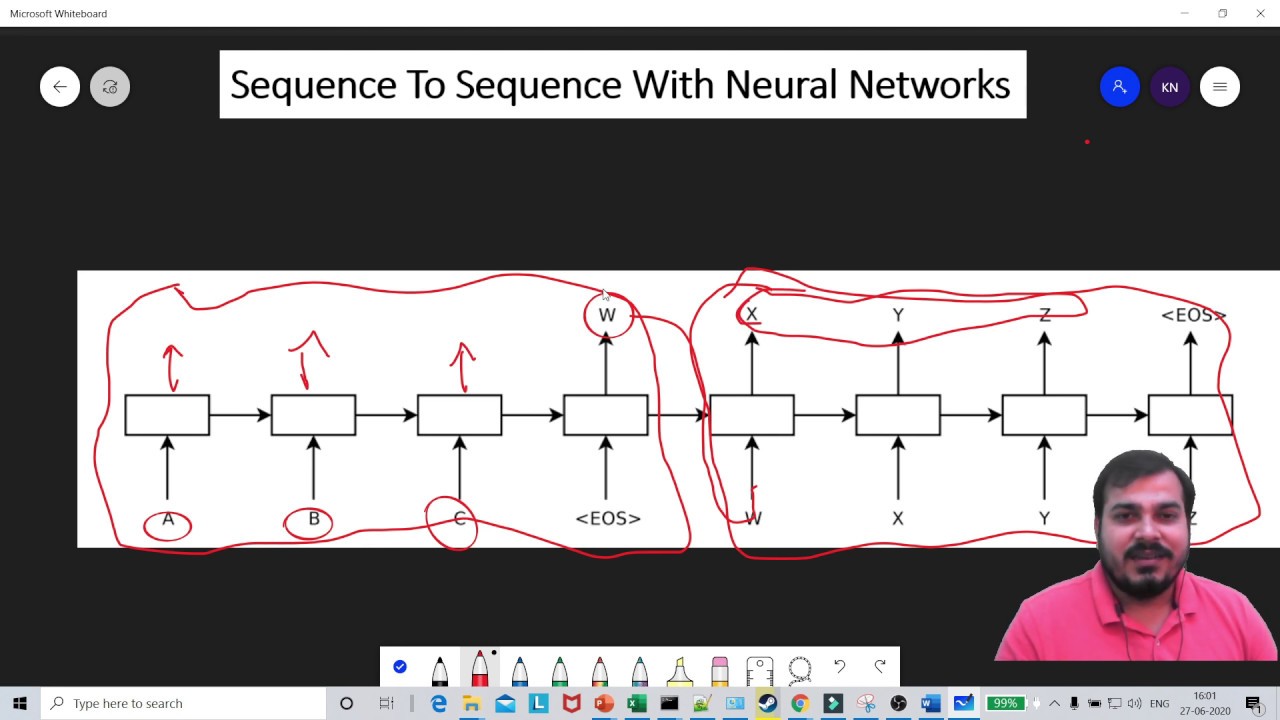
In sequence-to-sequence learning, we have two main components: the encoder and the decoder. The encoder takes input sentences and processes them to create a context vector. The context vector is then passed to the decoder, which uses it to generate the translated output. It’s important to note that we skip the output of the encoder, as our focus is on obtaining the context vector.
Dataset and Data Preprocessing
To train our model, we need a dataset with English and French sentences. We will be using a pre-existing dataset with over 100,000 English-French sentence pairs. You can find the dataset here.
Before feeding the dataset to the model, we need to preprocess it. This involves converting the sentences into numerical representations. We will use one-hot encoding, where each character is represented by a vector with a value of 1 for the corresponding character and 0 for all others. This ensures that the characters are represented in a consistent and numerical format.
Building the Model
We will build our model using the Keras library. The model consists of an LSTM layer for the encoder and a dense layer for the decoder. The encoder input shape is determined by the number of unique input tokens, the sequence length, and the feature dimension. Similarly, the decoder input shape is determined by the number of unique decoder tokens and the decoder sequence length.
Once we have defined the model architecture, we compile it using an optimizer, loss function, and evaluation metric. We then fit the model to our training data, incorporating a validation split.
Training and Evaluating the Model
After training the model, we can evaluate its performance using a validation dataset. In our case, we achieve an accuracy of around 87%. This model can be trained within 15 minutes on a typical laptop, making it efficient for practical use.
Generating Sentences
Once the model is trained, we can generate sentences using the decoder output. This is done by sampling from the output distribution, ensuring that the sentences are coherent and meaningful.
Conclusion
Neural machine learning language translation is an exciting field that opens up new possibilities for communication and understanding across languages. In this tutorial, we have explored how to implement sequence-to-sequence learning using machine learning and Keras. By following the steps outlined, you can build your own language translation model and contribute to bridging the linguistic gap.
FAQs
Here are some frequently asked questions about neural machine learning language translation:
-
What is sequence-to-sequence learning?
Sequence-to-sequence learning is a machine learning approach that enables us to translate sequences from one domain to another. It has proven to be effective in various applications, such as machine translation, image captioning, and speech recognition. -
What is a context vector?
A context vector is a numerical representation of a sentence that captures its meaning and context. It is obtained from the encoder and used as input for the decoder to generate the translated output. -
How does one-hot encoding work?
One-hot encoding is a technique used to represent categorical data, such as characters or words, in a numerical format. Each category is assigned a unique index, and a vector with a value of 1 is created for the corresponding category, with 0 values for all other categories. -
How long does it take to train a language translation model?
The time it takes to train a language translation model depends on various factors, such as the size of the dataset, the complexity of the model, and the computational resources available. With modern hardware, it is possible to train a model within a reasonable amount of time. -
How accurate is the language translation model?
The accuracy of a language translation model depends on the quality and size of the training data, as well as the complexity of the model. With the dataset used in this tutorial, we achieved an accuracy of around 87%. Further improvements can be made by using larger datasets and more advanced models.
Conclusion
In this tutorial, we explored the fascinating world of neural machine learning language translation using Keras. We discussed the concepts of encoder and decoder, dataset preprocessing, model building, training, and evaluation. By following this tutorial, you can gain a solid foundation in building your own language translation models. Happy translating!
