Welcome to Techal, where we dive deep into the world of technology. In this article, we’ll explore different modeling strategies for Natural Language Understanding (NLU). Whether you’re a language enthusiast or an engineer working on NLU projects, this article will provide valuable insights and strategies to enhance your understanding and improve your models.
Contents
Hand-Built Feature Functions
Let’s start with hand-built feature functions, which can be quite powerful for NLU problems. Some standard ideas include word overlap between the premise and hypothesis, word cross-product features, additional WordNet relations, edit distance, word differences, alignment-based features, and named entity recognition. These features allow your model to discover points of alignment and disalignment between the premise and hypothesis, aiding in powerful analysis.

Sentence Encoding Models
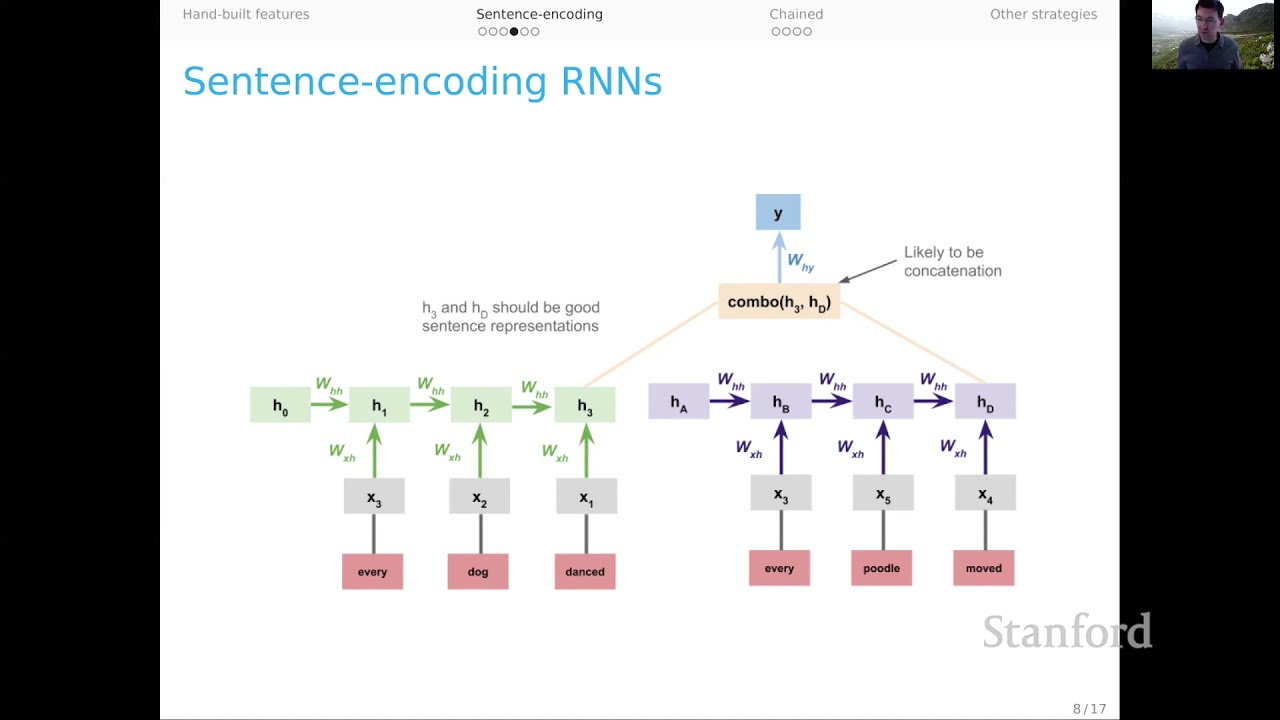
Moving into deep learning, sentence encoding models prove to be a highly effective approach for NLU. Distributed representations are utilized as features in this approach. By encoding the premise and hypothesis separately, the model has a chance to discover rich abstract relationships between them. Additionally, this approach facilitates transfer learning to other tasks beyond NLU, making it versatile and valuable for various applications.

Complex Models: Separate RNNs for Premise and Hypothesis
For more complex models, we can utilize separate recurrent neural networks (RNNs) for the premise and hypothesis. Each sentence is independently processed by its corresponding RNN. The final hidden representations of each RNN are then combined, typically through concatenation, and serve as the input for the classifier layer. This approach allows the models to learn interactions between the premise and hypothesis, opening doors for more nuanced analysis.

Chain Models: Merging Premise and Hypothesis
Alternatively, chain models merge the premise and hypothesis into one long sequence, which is then fed into a standard recurrent neural network (RNN). This approach is simple yet effective, as the premise establishes context for processing the hypothesis. By conditioning on one text while processing the other, the model gains valuable insights into the relationship between the two.

Combining Sentence Encoding and Chained Models
A hybrid approach involves using separate RNNs for the premise and hypothesis and chaining them together. The initial hidden state of the hypothesis is set as the final output state of the premise. This allows the models to learn that premise tokens and sequences have a different status than those appearing in the hypothesis. It provides a seamless transition between the two models, enhancing their understanding of the text.

These modeling strategies offer exciting opportunities to explore the depths of NLU. By considering various approaches and combining them with additional techniques like bidirectional RNNs, pooling, deeper hidden layers, and attention mechanisms, you can further enhance your models’ performance.
FAQs
Q: What are distributed representations?
A: Distributed representations, often utilized as features, involve looking up words in fixed embedding spaces and encoding them as vectors. These representations capture the semantic meaning of words and enable better analysis and understanding of text.
Q: Are hand-built feature functions still relevant in deep learning models?
A: Absolutely! Hand-built feature functions provide valuable insights and can enhance the performance of deep learning models. They allow models to discover important alignments, differences, and relationships between words and concepts within text.
Q: How can attention mechanisms improve NLU models?
A: Attention mechanisms enable models to focus on specific parts of the input text, allowing them to weigh the importance of different words or segments. This enhances the model’s understanding and improves its ability to capture context and relationships within the text.
Conclusion
In this article, we explored various modeling strategies for Natural Language Understanding. From hand-built feature functions to sentence encoding models and complex chain models, each approach offers unique insights into NLU problems. By combining these strategies and incorporating additional techniques, such as bidirectional RNNs, pooling, deeper layers, and attention mechanisms, you can create powerful NLU models that excel in understanding the complexities of human language.
For more information and to stay updated with the latest advancements in technology, visit Techal. Happy modeling!
Note: The original article contains lecture notes from the CS224U Natural Language Understanding course by Chris Potts. This Techal article is an interpretation and adaptation of the core concepts discussed in the lecture notes.
