Are you interested in mastering the art of pruning regression trees? Look no further! In this guide, we will dive deep into the world of regression tree pruning and explore a method called cost complexity pruning, also known as weakest link pruning. By the end of this article, you’ll understand how cost complexity pruning works and how it can help you build more accurate regression trees. So, let’s get started!
Contents
The Basics of Regression Trees
Before we delve into pruning techniques, let’s quickly recap regression trees. Regression trees are a powerful tool for predicting numerical values based on input variables. They work by partitioning the input space into a series of regions, where each region corresponds to a leaf node. The leaf nodes contain the predicted values for the corresponding input region.
The Issue of Overfitting
While regression trees can provide accurate predictions, they can also fall victim to overfitting. Overfitting occurs when the tree is too complex and perfectly fits the training data but fails to generalize well to new, unseen data. This can lead to poor performance when making predictions on real-world datasets.
Introducing Cost Complexity Pruning
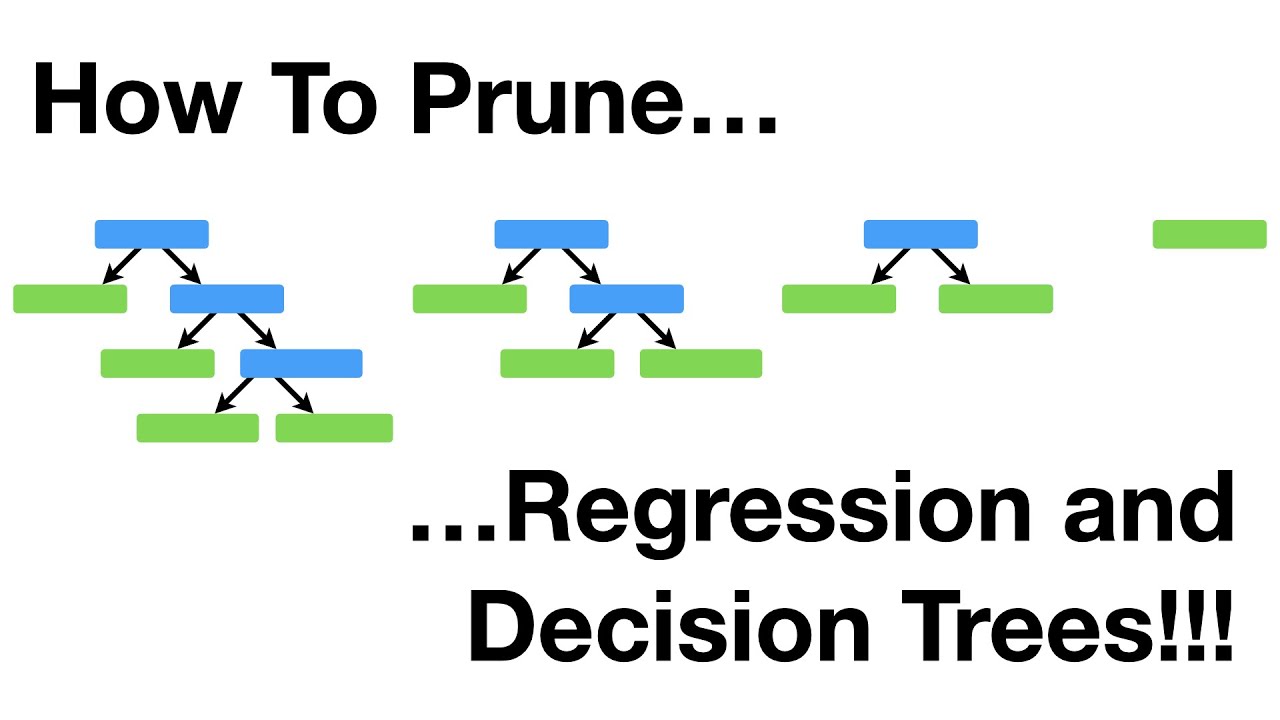
To combat overfitting, we can use a technique called cost complexity pruning, also known as weakest link pruning. The main idea behind pruning is to simplify the tree by removing some of the leaf nodes and replacing them with a single leaf node that represents the average value of a larger number of observations. This reduces the complexity of the tree and helps prevent overfitting.
How Cost Complexity Pruning Works
Cost complexity pruning involves calculating a tree score for each potential pruned tree. The tree score is calculated based on the sum of squared residuals for the tree and a tree complexity penalty, which accounts for the number of leaves in the tree. The goal is to find the tree with the lowest tree score, indicating the optimal level of pruning.
Finding the Optimal Tree
To find the optimal tree, we start with a full-sized regression tree that perfectly fits the training data. Then, we gradually increase a tuning parameter called alpha, which determines the strength of the tree complexity penalty. As alpha increases, the penalty for having more leaves in the tree becomes more significant.
We calculate the tree score for each value of alpha and select the tree with the lowest score. This tree strikes the perfect balance between simplicity and accuracy. By removing leaves and replacing them with larger clusters of observations, we ensure that the tree generalizes well to unseen data.
Fine-tuning with Cross-Validation
To further fine-tune our pruned tree, we employ cross-validation. We divide the data into multiple training and testing sets and repeat the pruning process for each fold. By evaluating the performance of the pruned trees on the testing data, we can determine the value of alpha that consistently yields the lowest sum of squared residuals.
Building the Final Pruned Tree
Once we have determined the optimal value for alpha, we go back to the original tree and select the subtree that corresponds to that value. This subtree becomes our final pruned tree, which strikes a balance between simplicity and predictive accuracy.
FAQs
Q1: What is the main goal of pruning regression trees?
The main goal of pruning regression trees is to prevent overfitting, ensuring that the tree generalizes well to new, unseen data.
Q2: How can cost complexity pruning help improve the performance of regression trees?
Cost complexity pruning simplifies the tree by removing some leaf nodes and replacing them with larger clusters of observations. This helps prevent overfitting and improves the tree’s ability to predict on unseen data.
Q3: Are there any tuning parameters involved in cost complexity pruning?
Yes, the main tuning parameter in cost complexity pruning is alpha. It determines the strength of the penalty for having more leaves in the tree. By adjusting alpha, we can find the optimal level of pruning for our specific dataset.
Conclusion
Congratulations on completing this comprehensive guide on pruning regression trees using cost complexity pruning! You now have a solid understanding of how to optimize your regression trees to improve their generalization capabilities. Happy pruning! For more exciting tech content, visit Techal.