Welcome to another exciting adventure with Techal! In this article, we will continue our exploration of backpropagation details, focusing on the fascinating world of the chain rule. If you haven’t already, make sure to check out Part 1, where we laid the groundwork for what we’ll be discussing today.
Contents
Unleashing the Power of the Chain Rule
The chain rule is a fundamental concept in calculus that allows us to compute derivatives of composite functions. In the context of backpropagation, it enables us to optimize the weights and biases of a neural network, bringing us one step closer to accurate predictions and robust models.

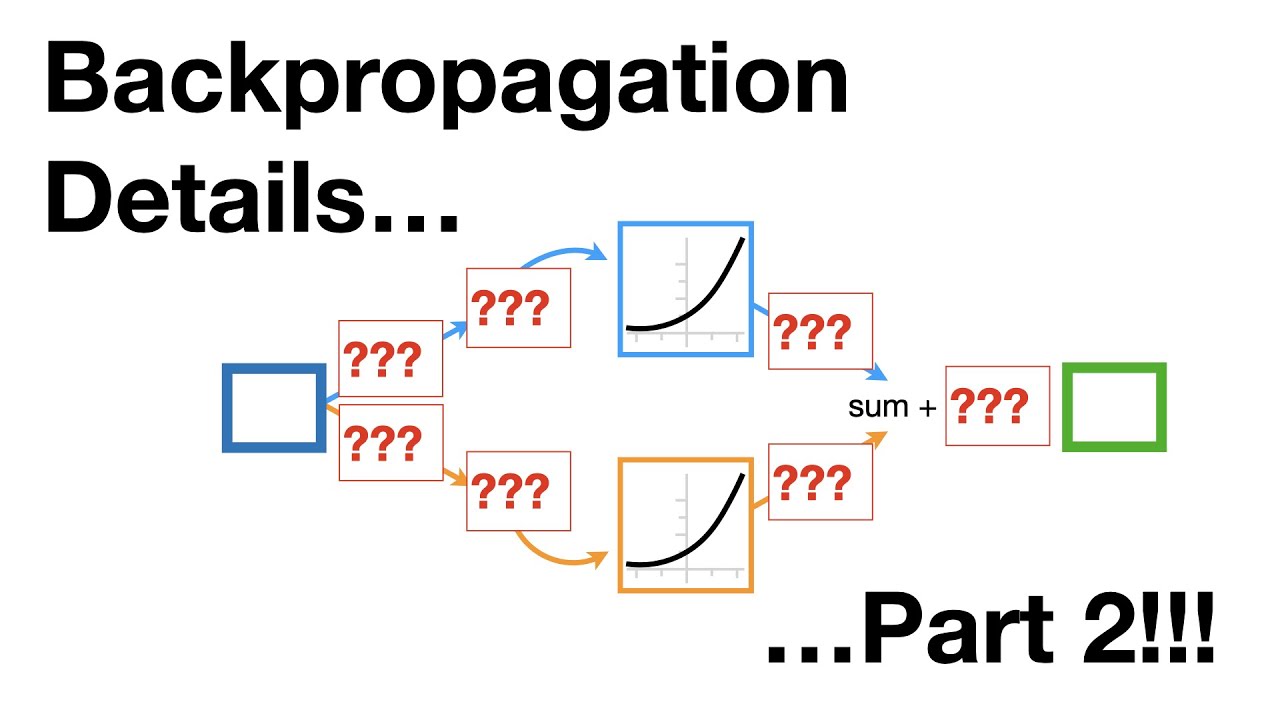
In Part 1, we derived the derivatives for bias b3 and weights w3 and w4. Now, armed with these derivatives, we can plug them into the gradient descent algorithm. However, our journey doesn’t end there. We need to delve deeper into the derivatives of the sum of the squared residuals with respect to w1, b1, w2, and b2.
Let’s start with w1. The neural network takes an input, i, multiplies it by w1, adds bias b1, and passes it through an activation function to get the activation value, y1. The chain rule tells us that the derivative of the sum of the squared residuals with respect to w1 is the derivative of the sum of the squared residuals with respect to the predicted values (y1) multiplied by the derivative of y1 with respect to x1 (the input for the activation function) multiplied by the derivative of x1 with respect to w1.
We can apply similar derivations for b1, w2, and b2. By combining these derivatives with the others we derived before, we can use gradient descent to optimize all the parameters simultaneously.
FAQ
Q: What is backpropagation?
Backpropagation is a key algorithm in training neural networks. It involves computing the gradients of the loss function with respect to the weights and biases of the network, then updating these parameters in a way that minimizes the loss.
Q: What is the chain rule?
The chain rule is a fundamental concept in calculus that allows us to compute derivatives of composite functions. In the context of backpropagation, it enables us to compute the derivatives of the sum of squared residuals with respect to each weight and bias in the neural network.
Q: How does gradient descent work?
Gradient descent is an optimization algorithm used to minimize a function iteratively. It works by taking steps proportional to the negative of the gradient of the function at the current point. By repeatedly updating the parameters in the direction of the steepest descent, gradient descent converges to a local minimum of the function.
Conclusion
Congratulations! You’ve successfully embarked on a thrilling journey through the complexities of backpropagation and the wonders of the chain rule. Armed with this knowledge, you’re now equipped to optimize the weights and biases of a neural network using gradient descent.
Remember, Techal is your trusted companion in the world of technology. Stay tuned for more informative and engaging content that will empower you with knowledge and keep you up to date with the ever-evolving world of technology.
Until next time, happy exploring!
Discreet hyperlink: Techal
