Welcome to Techal, your go-to source for all things technology. In this article, we’ll delve into the K-nearest neighbors (KNN) algorithm – a simple yet powerful method for classifying data.
Contents
Understanding the K-nearest neighbors Algorithm
At its core, the K-nearest neighbors algorithm allows us to classify unknown data by referring to its closest labeled neighbors. Let’s break it down step by step:
Step 1: Start with a Data Set
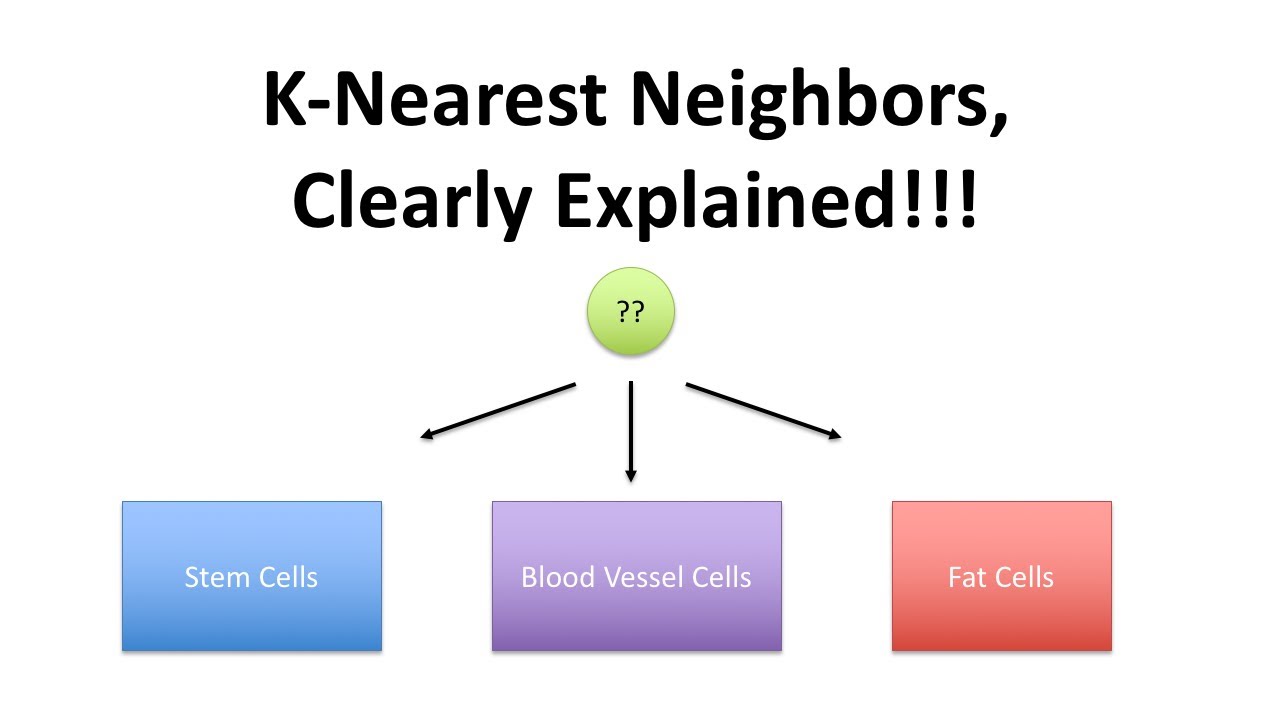
We begin with a dataset that contains known categories. For example, let’s consider different cell types from an intestinal tumor.
Step 2: Clustering the Data
Next, we cluster the data using techniques like Principal Component Analysis (PCA). This helps us visualize and understand the relationships between different data points.
Step 3: Classifying New Data
Now, imagine we have a new cell with an unknown category. To classify this cell, we look at its nearest annotated cells – the “nearest neighbors.”
If we set K as 1 (K=1), we only consider the closest neighbor to determine the category of the new cell. However, if K is larger, such as K=11, we consider the 11 nearest neighbors.
Handling Multiple Categories
If the new cell is located between two or more categories and K > 1, we let the neighbors cast their votes. The category with the most votes is assigned to the new cell.
Applied to Heat Maps
The K-nearest neighbors algorithm can also be used to analyze heat maps. By clustering and considering the nearest labeled cells, we can determine the category of an unknown cell based on its proximity to specific clusters.
FAQs
Q: How do I determine the best value for K?
A: Choosing the optimal value for K is not straightforward. Experimentation is key. By treating part of the training data as unknown and applying the K-nearest neighbors algorithm, you can assess how well the new categories align with the known ones. Keep in mind that low values for K (like K=1 or K=2) can be noisy, while large values smooth over data but risk overpowering categories with few samples.
Conclusion
The K-nearest neighbors algorithm provides a straightforward approach to classifying data based on its proximity to labeled examples. Whether you’re analyzing cell types or delving into heat maps, the KNN algorithm offers valuable insights. Stay tuned for more exciting tech insights from Techal!
- For more information about K-nearest neighbors, visit Techal.
